Потоки thread
Напишем программу в 2 потока, каждый из которых по очереди печатает свой номер (0 или 1) и далее числа от 0 до 9.
Синхронизацию сделаем на Event.
import threading
def writer(x, event_for_wait, event_for_set):
for i in range(10):
event_for_wait.wait() # wait for event
event_for_wait.clear() # clean event for future
print(x, i)
event_for_set.set() # set event for neighbor thread
# init events
e1 = threading.Event()
e2 = threading.Event()
# init threads
t1 = threading.Thread(target=writer, args=(0, e1, e2))
t2 = threading.Thread(target=writer, args=(1, e2, e1))
# start threads
t1.start()
t2.start()
e1.set() # initiate the first event
# join threads to the main thread
t1.join()
t2.join()
Методы класса Thread
| Метод | Описание |
|---|---|
| start() | запускает thread; вызывается 1 раз, перед run() |
| run() | то, что должен делать thread. Thread.run вызывает метод, переданный в аргументах конструктора с переданными там же аргументами. |
| join(timeout=None) | Ждет, пока этот тред закончится или закончится таймаут. Возвращает всегда None. Вызывайте is_alive(), чтобы узнать жив тред или нет. RuntimeError при попытке join текущий тред (дедлок). |
| threading.enumerate() | список всех живых тредов |
| name | имя треда, используется для идентификации, устанавливается в конструкторе. Может совпадать у разных тредов. |
| iden | идентификатор треда, целое число != 0, может быть повторно использован для нового треда после окончания старого. get_ident() |
| daemon | для треда-демона нужно установить в True до вызова функции start() |
Синхронизация на Event
Объект Event содержит внутренний флаг (изначально false), который устанавливается в true методом set(), и сбрасывается методом clear(). Метод wait(timeout=None) блокирует, пока флаг не станет true или не истечет timeout (дробное число секунд).
Метод wait вернет True, если флаг был/стал true. В противном случае (истек таймаут) он вернет False. До 3.1 всегда возвращалось None.
Код легко масштабируется. Добавим еще один thread:
import threading
def writer(x, event_for_wait, event_for_set):
for i in range(10):
event_for_wait.wait() # wait for event
event_for_wait.clear() # clean event for future
print(x, i)
event_for_set.set() # set event for neighbor thread
# init events
e1 = threading.Event()
e2 = threading.Event()
e3 = threading.Event() # ++++
# init threads
t1 = threading.Thread(target=writer, args=(0, e1, e2))
t2 = threading.Thread(target=writer, args=(1, e2, e3)) # модифицирована
t2 = threading.Thread(target=writer, args=(3, e3, e1)) # ++++
# start threads
t1.start()
t2.start()
t3.start() # +++++
e1.set() # initiate the first event
# join threads to the main thread
t1.join()
t2.join()
t3.join()
Global Interpreter Lock (GIL)
Концепция Global Interpreter Lock - в каждый момент времени только 1 поток (thread) может исполняться 1 процессором.
- Плюс: разные потоки могут легко использовать одни и те же переменные. Исполняемый поток получает доступ ко всему окружению. Получаем thread safety (потокобезопасность).
- Минус: накладные расходы на переключение потоков.
Напишем миллион строк в файл в одном потоке и измерим время выполнения программы. Получим 0.35 сек.
with open('test1.txt', 'w') as fout:
for i in range(1000000):
print(1, file = fout)
Теперь перепишем код в 2 потока по полмиллиона записей в каждом (без синхронизации потоков):
from threading import Thread
def writer(filename, n):
with open(filename, 'w') as fout:
for i in range(n):
print(1, file=fout)
t1 = Thread(target=writer, args=('test2.txt', 500000,))
t2 = Thread(target=writer, args=('test3.txt', 500000,))
t1.start()
t2.start()
t1.join()
t2.join()
По сути работы столько же, сколько у предыдущей программы. И ожидаем, что работать она будет примерно столько же. А по факту работает она от 0.7 до 7 секунд. Почему?
Старый GIL (до 3.1)
В старом GIL обычный цикл изменения одной переменной миллион раз давал следующие результаты на Dual-Core 2Ghz Macbook, OS-X 10.5.6
| Вариант | Время |
|---|---|
| Последовательный запуск | 24.6 sec |
| 2-thread запуск | 45.5 sec |
| 2-thread запуск, отключен 1 CPU core | 38.0 sec |
В чем дело?
Старый GIL основывался на тиках интерпретатора и повторяющихся сигналах на условной переменной (cond. var)
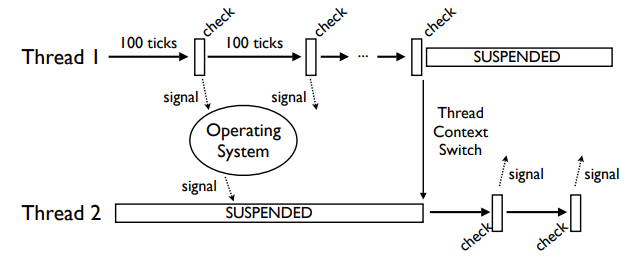
В случае 2 core должны тоже выполняться по очереди.
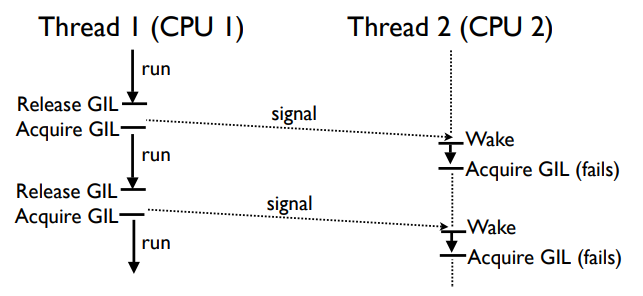
Второй thread может прождать 100 сек в безуспешных попытках получить GIL, пока одна из них не закончися успехом.
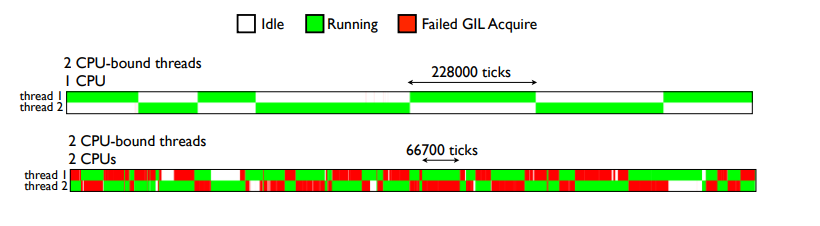
Посмотрим, как меняется время при Failed GIL Acquire при выключении 1 core:
Новый GIL
Все так же основывается на сигналах и условных переменных, но считает не тики, а секунды, которые устанавливаются в sys.setcheckinterval().
Решение о переключении потоков связано с глобальной переменной
static volatile int gil_drop_request = 0; /* Python/ceval.c */
Thread работает в интерпретаторе до тих пор, пока значение этой переменной не станет 1. В этот момент тред обязан отпустить GIL.
Пока 1 тред, он работает бесконечно (не прерываясь), не отпуская GIL и не посылая сигналов.
Когда появляется второй тред, он приостановлен (suspended), потому что у него нет GIL. Каким то образом должен получить его от первого треда.
Второй тред выполняет cv_wait на GIL с ограничением по времени.
Тред 2 будет ждать, когда тред 1 добровольно освободит GIL (например, во время I/O или когда соберется спать).
Если GIL отдается добровольно, то треду 2 будет послан сигнал от треда 1, когда тред 1 заснет. Тогда начнет выполняться тред 2.
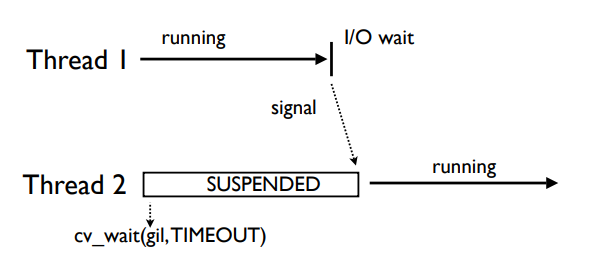
Если же до окончания таймаута в cv_wait тред 2 не получил GIL, то он посылает gil_drop_request, выставляя переменную gil_drop_request=1. После этого он опять ждет в cv_wait.
Тред 1 вынужден отдать GIL: он заканчивает выполнение текущей инструкции, отпускает GIL и посылает сигнал, что GIL свободен. Далее он начинает ждать сигнал (что GIL взят). Тред 2 захватывает GIL и посылает сигнал, что GIL взят. Т.е. "битва за GIL" исключена.
Далее повторяется ситуация, но теперь тред 2 выполняется, а тред 1 - подвешен.
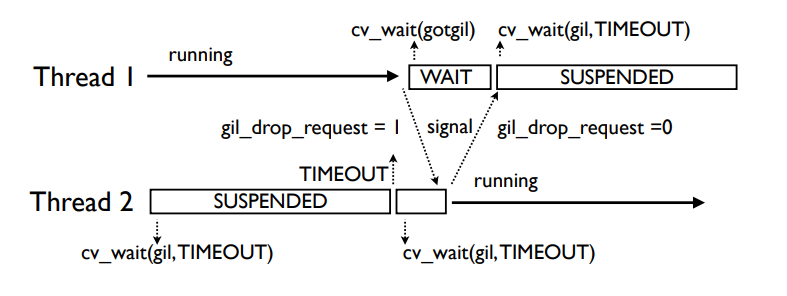
По умолчанию таймаут для переключения треда 5 мс. Для сравнения - по умолчанию таймаут для переключения контекста в большинстве систем 10 мс. Настраивается в sys.setswitchinterval().
Аналогично система работает для многих тредов. По окончанию таймаута тред может установить gil_drop_request=1, только если во время таймаута не было переключения тредов (добровольного или принудительного). Если у нас много соревнующихся тредов, только один из них может установить gil_drop_request за время таймаута.

Тред 3 и тред 4 после первого таймаута не инициируют установку gil_drop_request=1, потому что пока был их таймаут, тред 2 получил GIL (т.е. был thread switch).
После второго таймаута один из них (кто быстрее) сможет инициировать выставление gil_drop_request.
Не факт, что именно тот тред, который выставил gil_drop_request, получит GIL. Это больше зависит от ОС. На рисунке тред 2 выполнил gil_drop_request, а ОС решила, что выполняться будет тред 3.

Теперь по производительности многотредовая программа не намного хуже, чем программа в 1 тред. (До 100 тредов измеряли и получали приемлемые результаты).
Новый GIL позволяет треду выполняться 5 мс, не зависимо от других тредов или приоритетов I/O. Это значит, что треды, требующие ЦПУ могут на некоторое время блокировать треды, требующие I/O.
Таким образом мы исключили избыточное переключение контестов. Если вас не устраивает время ответа в 5 мс, его можно настроить, но...
Обратите внимание
- долгие вычисления и С/С++ расширения могут блокировать переключение тредов;
- переключение тредов не preemptive (кооперативное, а не вытесняющее);
- таким образом, если операция в C extension занимает 5 секунд, вы будете должны подождать это время, пока GIL не отпустят (в старом GIL было такое же поведение).
Вывод: Не стоит использовать многотредовость для распараллеливания вычислений. Многотредовость - для обработки событий.
Назад, в историю:
- модуль thread - устарел, переименован в _thread (для обратной совместимости)
- модуль threading - пользуемся им.
Вариант создания нити - наследуемся от Thread
Выше пример не требовал создания новых классов, новый тред создавался при вызовые конструктора класса Thread, которому передавалась функция и ее аргументы.
Можно пойти другим путем - написать класс-наследник от Thread.
| Методы класса | Метод Описание |
|---|---|
| run(): | Это функция точки входа для любого потока. |
| start(): | Способ start() запускает поток, когда вызывается метод run. |
| join([time]): | Метод join() позволяет программе ожидать оканчиваются. |
| isAlive(): | Метод isAlive() проверяет активную нить. |
| getName(): | Метод getName() возвращает имя потока. |
| setName(): | Метод setName() обновляет имя потока. |
# Многопоточность в Python: пример кода для отображения текущей даты в потоке.
#1. Определить подкласс, используя класс thread.
#2. Создать экземпляр подкласса и вызвет поток.
import threading
import datetime
class myThread (threading.Thread):
def __init__(self, name, counter):
threading.Thread.__init__(self)
self.threadID = counter
self.name = name
self.counter = counter
def run(self):
print "Запуск " + self.name
print_date(self.name, self.counter)
print "Выход " + self.name
def print_date(threadName, counter):
datefields = []
today = datetime.date.today()
datefields.append(today)
print "%s[%d]: %s" % ( threadName, counter, datefields[0] )
# Создание новой нити
thread1 = myThread("Нить", 1)
thread2 = myThread("Нить", 2)
# Запуск новой нити
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print "Выход из программы!!!"
Синхронизация тредов
Синхронизация тредов через Lock
У объекта Lock 2 метода:
- acquire(blocking=True, timeout=-1) - ждать, когда лок освободят, не более timeout секунд;
- release() - освобождает лок.
Для каждого разделяемого ресурса пишем свой собственый лок
Для избежания взаимных блокировок (deadlock) важно освобождать лок и в случае ошибок. Т.е. пишем его в try-finally блоке:
lock.acquire()
try:
... доступ к разделяемому ресурсу
finally:
lock.release() # освободить блокировку, что бы ни произошло
Начиная с питона 2.5 есть возможность писать гарантированно освобождаемый лок (Lock, RLock, Condition, Semaphore, BoundedSemaphore) с конструкцией with. То же самое:
with lock:
... доступ к разделяемому ресурсу
Если хочется избежать блокировки потока методом acquire, если лок уже кем-то захвачен, то нужно вызывать его с аргументом blocking=False, тогда вызов этого метода не блокирует и сразу же возвращает False, если блокировка кем-то захвачена:
if not lock.acquire(False):
... не удалось заблокировать ресурс
else:
try:
... доступ к разделяемому ресурсу
finally:
lock.release()
Этот код НЕ гарантирует, что мы быстро получим лок в acquire:
if not lock.locked():
# другой поток может начать выполняться перед тем как мы перейдём к следующему оператору
lock.acquire() # всё равно может заблокировать выполнение
Проблемы
Обычной блокировке (объекту типа Lock) всё равно, кто её захватил; если блокировка захвачена, любой поток при попытке её захватить будет заблокирован, даже если этот поток уже владеет этой блокировкой в данный момент.
Все работает, даже если эти функции (допустим, они обрабатывают две независимые части объекта) выполняются двумя разными потоками:
lock = threading.Lock()
def get_first_part():
lock.acquire()
try:
... получить данные первой части разделяемого объекта
finally:
lock.release()
return data
def get_second_part():
lock.acquire()
try:
... получить данные второй части разделяемого объекта
finally:
lock.release()
return data
НО! Если хотим добавить функцию, которая обрабатывает сразу весь объект. Этот код работать не будет:
def get_both_parts():
first = get_first_part()
# тут может вклиниться другой поток, изменить объект и он станет неконсистентным
second = get_second_part()
return first, second
Нужно локать весь объект целиком! Но этот код тоже не работает:
def get_both_parts():
lock.acquire() # держим блокировку
try:
first = get_first_part() # тут не можем получить блокировку, потому что ее держит тот же поток!
second = get_second_part()
finally:
lock.release()
return first, second
Можно сделать отдельный лок на блокировку объекта целиком:
lock = threading.Lock()
lock_whole = threading.Lock()
def get_both_parts():
with lock_whole:
first = get_first_part()
second = get_second_part()
return first, second
def get_first_part():
lock.acquire()
try:
... получить данные первой части разделяемого объекта
finally:
lock.release()
return data
def get_second_part():
lock.acquire()
try:
... получить данные второй части разделяемого объекта
finally:
lock.release()
return data
Но лучше использовать лок, который позволяет повторно себя брать тому же потоку, так называемый reenterable lock (RLock).
RLock
lock = threading.Lock()
lock.acquire()
lock.acquire() # вызов заблокирует выполнение
lock = threading.RLock()
lock.acquire()
lock.acquire() # вызов не заблокирует выполнение
Если в предыдущем примере наш лок будет r-локом, то функции get_first_part и get_second_part оставляем без изменений, но переписываем get_both_parts
lock = RLock()
def get_first_part():... так же ....
def get_second_part():... так же ....
def get_both_parts():
lock.acquire() # берем лок, глубина вызова +1
try:
first = get_first_part() # повторный лок, глубина вызова +1; освобождение, глубина вызова -1
second = get_second_part() # повторный лок, глубина вызова +1; освобождение, глубина вызова -1
finally:
lock.release() # освобождение, глубина вызова -1, лок освобожден полностью!
return first, second
Еще механизмы синхронизации
Аналогичны синхронизации потоков. Давайте вторую половину рассмотрим там.
Данные, специфичные для одного треда
mydata = threading.local()
mydata.x = 1